3D virtual try-on aims to synthetically fit a target clothing image onto a 3D human shape
while preserving realistic details such as pose, identity of the person. Existing methods heavily depend on
annotated 3D shapes and garment templates
which limits their practical use. While 2D virtual try-on is another alternative, it ignores the
3D body information
and cannot fully represent the human body. Recently, M3D-VTON
was proposed to generate
textured 3D try-on meshes only from 2D images of person and clothing by formulating the 3D try-on problem
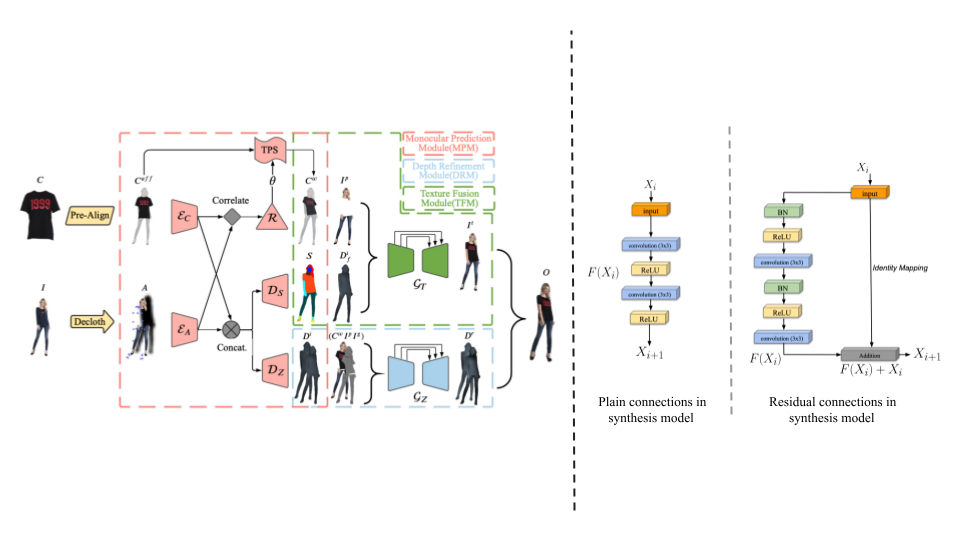
as 2D try-on and depth estimation. However, we find that the synthesis model in the M3D-VTON pipeline
uses a simple U-Net architecture. We hypothesize that this is insufficient to synthesize body parts
and model complex relation between front and back parts of clothing only from the 2D clothing image,
ultimately leading to unrealistic 3D try-on results. We improve this by
implementing residual units in the existing synthesis model. Studying it’s effect demonstrates that
it improves 2D try-on outputs, mainly by differentiating between front and back part of clothing,
preserving logo of clothing and reducing artifacts.
This ultimately results in better textured
3D try-on mesh. Benchmarking our method on the MPV3D dataset shows that it performs better than
previous works significantly.

|